
 Global
Global China
China Austria
Austria Australia
Australia Belgium
Belgium Colombia
Colombia Denmark
Denmark Deutschland
Deutschland España
España مصر
مصر France
France Greece
Greece Guatemala
Guatemala Hong Kong
Hong Kong Ireland
Ireland Ísland
Ísland מדינת ישראל
מדינת ישראל Luxembourg
Luxembourg México
México Netherlands
Netherlands New Zealand
New Zealand Norge
Norge Österreich
Österreich Portugal
Portugal Singapore
Singapore Sverige
Sverige ไทย
ไทย UAE
UAE United Kingdom
United Kingdom Poland
Poland Qatar
Qatar Switzerland
Switzerland Uruguay
Uruguay
China, June 29, 2026 — XPENG (NYSE: XPEV, HKEX: 9868), a leading China-based high-tech company, shared key insights at the CVPR 2026 Workshop on Foundation Model Deployment for Embodied Intelligence, hosted in Denver, U.S. this June. Xianming Liu, Head of XPENG Group's General Intelligence Center, disclosed for the first time the complete technical roadmap of XPENG's World Model. He proposed that proactive reasoning, controllable generation, and long-horizon forecasting are three indispensable capabilities for a high-performance World Model, the core prerequisites for deploying World Models in the field of autonomous driving.
In the first half of this year, XPENG's R&D team published a suite of world-model-focused academic reports, including X-World, X-Foresight, and X-Cache, which systematically disassembled R&D methodologies around controllable generation and long-horizon forecasting. Recently, addressing the critical challenge of enabling models to think proactively and pushing the upper limit of predictive performance, XPENG Group officially released the X-Mind technical framework. By embedding a predictive World Model, X-Mind endows vehicle-side agents with an efficient visual Chain-of-Thought, successfully resolving the tension between cognitive reasoning and real-time computation, thereby establishing an entirely new technical paradigm for achieving genuinely safe, human-like autonomous driving.
Moving Beyond Intuitive Driving to " Proactive Reasoning"
Traditional mainstream industry solutions remain confined to a reactive mapping stage of "perception-to-action". This is highly analogous to a driver stepping on the accelerator while staring solely at the instantaneous frame directly ahead, lacking any explicit prediction capability regarding the spatial-temporal evolution of the physical world.
Specifically, the notable shortcomings are twofold. First, text-based reasoning struggles to accurately express complex environmental geometry. Second, predicting future raw images introduces a massive amount of high-frequency, redundant textural data, while lacking the deep semantic information that is vital for autonomous driving tasks.
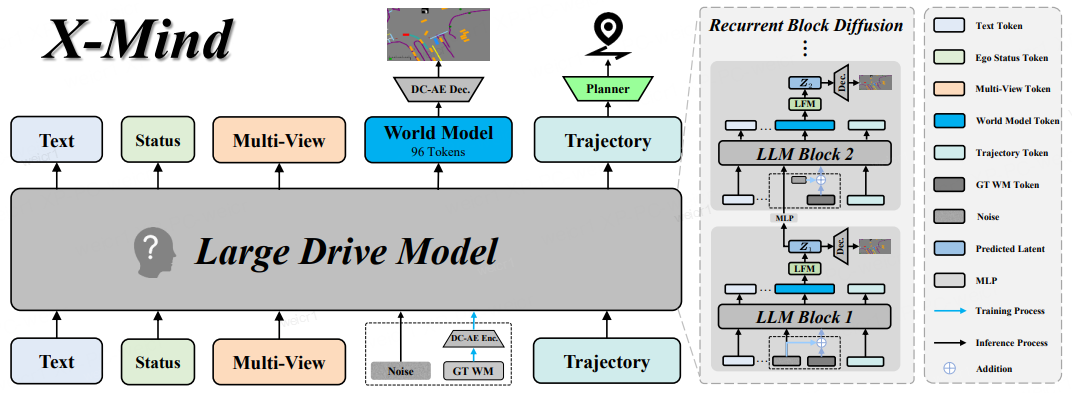
Overall architecture of X-Mind. The PWM is embedded within the large drive model. Recurrent Block Diffusion executes progressive denoising across hierarchical internal layers in a single forward pass to generate a compact abstract sketch. Conditioned on this anticipated physical future, the planner derives the optimal ego vehicle trajectory. Blue arrows denote training data flow; black arrows illustrate inference.
Based on these insights, XPENG's R&D team introduced an innovative approach: allowing the model to execute a highly efficient simulation inside its "brain" before outputting actions. This instantiates a Visual Chain-of-Thought (Visual CoT), executing explicit spatial-temporal rollouts prior to action generation. Consequently, the vehicle can anticipate like a seasoned driver, ensuring every planned path accounts for changes in future traffic flow and enables superior defensive driving. X-Mind stands as a powerful tool to resolve the conflict between cognitive reasoning and real-time deployment, empowering Vision-Language-Action (VLA) models with proactive physical reasoning.
X-Mind: Breaking the Black Box, Evolving from Physiological Reflex to Cognitive Deliberation
Similar to X-Foresight, X-Mind is dedicated to integrating Predictive World Models into end-to-end driving models. However, they differ clearly in their forms of expression, technical focus, and how they empower the on-vehicle VLA model:
X-Foresight is architecturally fused with the VLA model, jointly predicting multi-view future imagery and ego-vehicle actions within a unified token space to underpin core decision-making. It focuses on "seeing" future frames to understand how the world evolves.
X-Mind serves as a thinking canvas for the VLA, executing high-frequency cognitive reasoning under constrained vehicle-side computing power, and visually interpreting the underlying logic of model decisions via a Visual Chain-of-Thought. It focuses on establishing a human-like, highly efficient reasoning process prior to acting.
Together, these two frameworks will drive XPENG’s VLA model to evolve into a General Physical AI equipped with physical common sense, advanced forecasting capabilities, and fully transparent reasoning.
Centering around the core goal of "thinking fast and thinking clearly," X-Mind transforms reactive black-box mapping into predictive, explicit cognitive reasoning. In simple terms, it visualizes and transparently clarifies the logic underlying model decisions through three core pillars:
1. Thought Sketch: Achieving Efficient Visual Thinking Representation
Inspired by human cognitive psychology, X-Mind abandons the obsession with high-definition textures, turning instead to construct a "cognitive canvas" that merges Bird's-Eye-View (BEV) layouts with abstract driving priors.
What does a Thought Sketch include? Physical scene elements (lane lines, obstacles), dynamic traffic light statuses, adaptive navigation intentions, and compliant speed profiles.
What are its advantages? Utilizing a Deep Compression Autoencoder (DC-AE), X-Mind compresses a 12-frame future world rollout into a mere 96 tokens. This proves that compared to highly redundant images or expensive 3D reconstruction, the Thought Sketch effectively filters out planning-irrelevant texture interference, retaining only core semantic priors like road topologies, traffic light states, and navigation intents. It fundamentally resolves the computational bottlenecks brought by long context windows, rendering "thinking" lightweight and exceptionally efficient.
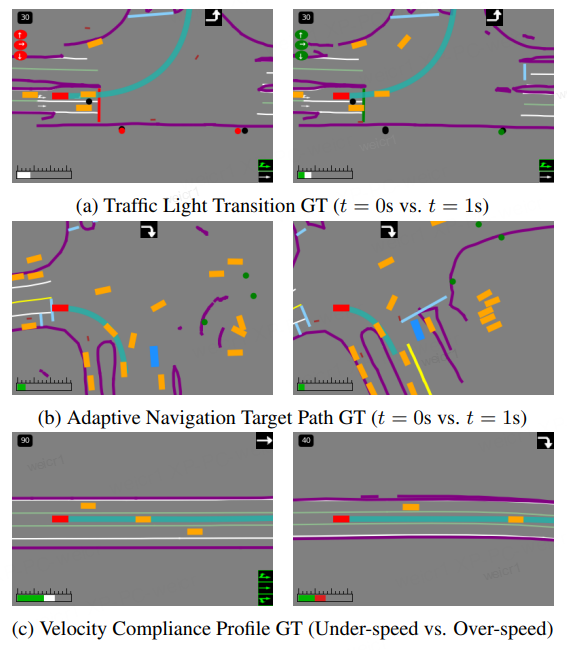
Visualization of the Structured Abstract Sketch
Annotations of this type serve as high-fidelity supervisory signals for training world model, covering: (a) dynamic traffic light states, (b) adaptive navigation intents, (c) velocity compliance profiles. Dense, structurally featured annotations are critical for the model to learn complex physical and semantic driving rules.
2. Recurrent Block Diffusion: Generating High-Quality Future Rollouts
Traditional diffusion models require multiple iterations to generate future frames, causing severe time latency. X-Mind innovatively designs a Recurrent Block Diffusion (RBD) mechanism, which internalizes generation across different internal layers of the large driving model, achieving high-quality future rollouts within a single forward pass.
The XPENG R&D team conducted comparative experiments among the standard baseline, single-step denoising, and the RBD mechanism. The experimental data shows that the image generation quality of RBD is vastly superior to single-step denoising (FID: 9.59 vs 67.30), while its inference latency remains nearly identical, successfully breaking the bottleneck between cognitive reasoning and real-time deployment.
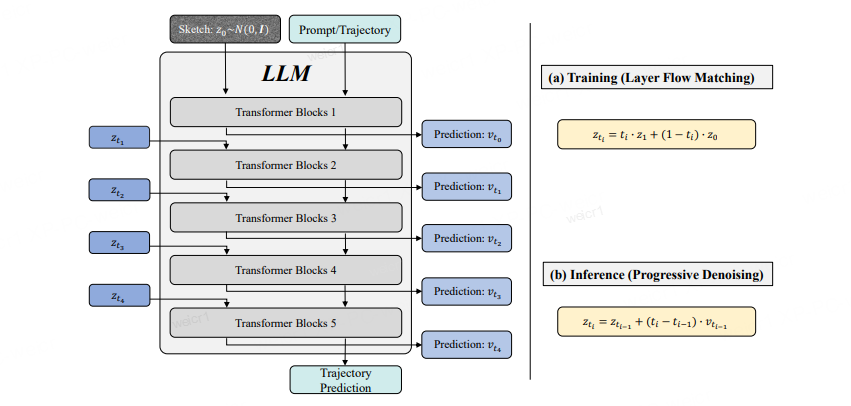
Overview of Recurrent Block Diffusion
Transformer layers are divided into five blocks; during training, sketch token features at each block are replaced with linear combinations of noise and ground truth. During inference, outputs of preceding blocks feed subsequent blocks via Euler integration with a fixed time step — all within one LLM forward pass.
3. Chain-of-Thought Visualization: Intuitively Displaying Proactive reasoning
Through the visualization of the Chain-of-Thought (CoT), experiments intuitively demonstrate how the model projects future obstacle occupancy and lane connectivity onto its mental canvas before executing an action. The planner no longer blindly fits trajectories; instead, it derives the optimal ego-trajectory based on inverse dynamics. This means every planned path conforms strictly to physical laws and fully anticipates changes in future traffic flows.
This visualization of "proactive reasoning" serves not only to validate algorithmic performance but also stands as a critical tool for building user trust and streamlining software debugging.
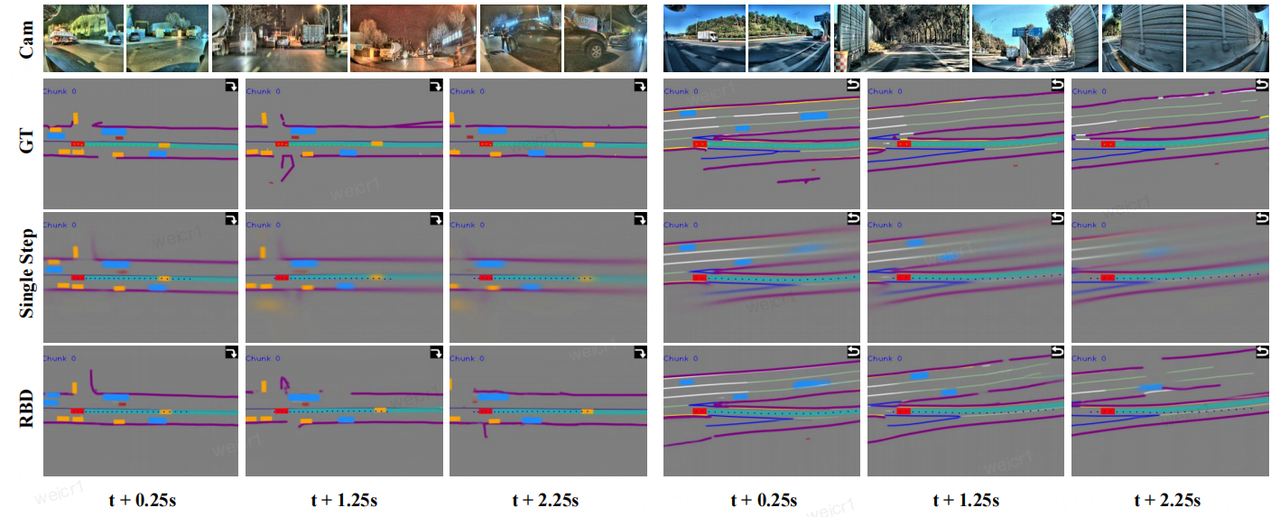
Qualitative comparison of future BEV predictions. The images illustrate the results of future spatial inference under both daytime and nighttime scenarios. Compared to baseline methods based on single-step generation (middle row), the Recursive Block Diffusion (RBD) framework proposed by X-Mind (bottom row) yields highly accurate and temporally coherent predictions. Crucially, even in cases where dynamic objects are absent from Ground Truth (GT) supervision, the RBD framework demonstrates a cognitive capability to predict the motion of dynamic objects.
Real-World Validation: Conquering Long-Tail Scenarios and Elevating Safety
Trained on a dataset containing hundreds of millions of real-world data frames, X-Mind has already demonstrated outstanding performance. Whether confronting sudden braking by leading vehicles, highway ramp merging, or complex intersection maneuvers, X-Mind anticipates obstacle occupancy and causal chains in the scene well in advance. Comparative experimental data indicates:
Precision Breakthrough: Compared to conventional VLA models, X-Mind significantly reduces both lateral and longitudinal Average Displacement Error (ADE) in trajectory prediction. Crucially, in complex long-tail scenarios, safety and traffic compliance are substantially enhanced.
Efficiency Revolution: Compared to alternative solutions that utilize raw images or 3D Gaussian Splatting (3DGS) as intermediate representations, X-Mind exhibits ultra-low inference latency, making it highly feasible for large-scale mass production on resource-constrained, automotive-grade chips.
The Critical Puzzle Piece: Completing XPENG's Physical AI Foundational Model Lineage
The release of X-Mind provides a solution to the arduous challenge of explicitly expressing the "thinking process" under vehicle-side computing constraints. Together with X-World and X-Foresight, it constitutes the core R&D lineage of XPENG's Physical AI Foundational Model, successfully activating the three core competencies: proactive reasoning, controllable generation, and long-horizon forecasting. This enables the model to not only learn "how to act" but also understand "how the world changes after an action."In recent years, the XPENG R&D team has consistently elevated foundational model performance by scaling up models, data volumes, and training objectives, continuously exploring the limits of scaling laws. As the capabilities of the VLA2.0 continue to rise, its comprehensive system formed across environmental understanding, reasoning, decision-making, and action execution is accelerating its extension into broader embodied intelligence scenarios. XPENG Group will accelerate the development and mass-production application of breakthrough technologies, continuing to shape the future blueprint driven by Physical AI.
---
About XPENG
Founded in 2014, XPENG is a leading Chinese AI-driven mobility company that designs, develops, manufactures, and markets Smart EVs, catering to a growing base of tech-savvy consumers. With the rapid advancement of AI, XPENG aspires to become a global leader in AI mobility, with a mission to drive the Smart EV revolution through cutting-edge technology, shaping the future of mobility.
To enhance the customer experience, XPENG develops its full-stack advanced driver-assistance system (ADAS) technology and intelligent in-car operating system in-house, along with core vehicle systems such as the powertrain and electrical/electronic architecture (EEA). Headquartered in Guangzhou, China, XPENG also operates key offices in Beijing, Shanghai, Silicon Valley, and Amsterdam. Its Smart EVs are primarily manufactured at its facilities in Zhaoqing and Guangzhou, Guangdong province.
XPENG is listed on the New York Stock Exchange (NYSE: XPEV) and Hong Kong Exchange (HKEX: 9868).
For more information, please visit https://www.xpeng.com/.
Contacts:
For Media Enquiries:
XPENG PR Department
Email: pr@xiaopeng.com
Source: XPENG





